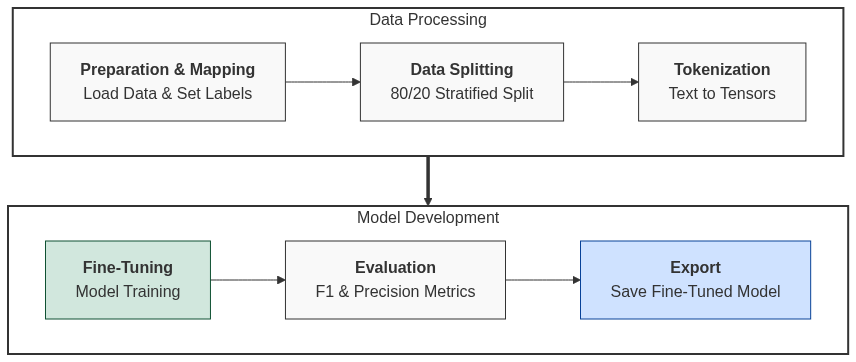
Imports and Data Loading
The necessary libraries are loaded:
- Pandas: A tool that allows us to analyze and manipulate data with Python.
- PyTorch: The library that helps us with machine learning tasks to create learning models and neural networks.
- Transformers: Allows us to download, train, and use models.
- scikit-learn: Used to obtain the model's metrics.
import os
import pandas as pd
import torch
from datasets import Dataset
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
from sklearn.model_selection import train_test_split
from transformers import (
AutoModelForSequenceClassification,
AutoTokenizer,
Trainer,
TrainingArguments,
)
df = pd.read_csv("data.csv")Label Preparation
Here we convert our labels ("normal", "critical", and "highly_critical") into numbers (0, 1, 2). This is necessary because neural networks only understand numerical data.
label_map = {"normal": 0, "critico": 1, "muy_critico": 2}
df["label"] = df["label"].map(label_map)Dataset Splitting
We allocate a percentage of the dataset for testing and another for training—in this case, 80% for training and 20% for testing.
We perform this split to ensure the model actually learns to identify patterns rather than just memorizing data. Additionally, we avoid overfitting, without this split, we wouldn't be able to determine if the model is performing well. By hiding a portion of the data, we force the model to find more general patterns that work in any context.
train_df, test_df = train_test_split(
df, test_size=0.2, random_state=42, stratify=df["label"]
)The stratify parameter ensures that both the training and testing groups maintain the same proportion of cases, avoiding biases.
Tokenization
This process is vital for translating text into a format that a computer can process mathematically. It is the bridge between raw text and PyTorch tensors.
model_name = "pysentimiento/robertuito-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
def tokenize_function(examples):
return tokenizer(
examples["text"], padding="max_length", truncation=True, max_length=128
)
train_dataset = train_dataset.map(tokenize_function, batched=True)Model Configuration
In this step, we download the model architecture, which is specifically designed for classifying text sequences.
This architecture is prepared to receive a sentence and output probabilities for different categories.
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=3)num_labels=3: By setting this to 3, we are telling the model to remove the original output layer and replace it with a new one containing exactly 3 neurons. These neurons correspond to our levels: Normal, Critical, and Highly Critical.
Metrics
Metrics allow us to evaluate how well our model is performing and are a key part of the process.
There are 4 key metrics:
Accuracy: The total percentage of correct predictions.
Precision: Out of all the cases the model labeled as "X", how many were actually "X"?
Recall: Out of all the cases that exist in reality, how many was the model able to capture?
F1-score: Indicates how good the model is at detecting "Highly critical" cases without confusing them with "Normal" ones. A high F1-score means the model is balanced and reliable across all three risk levels.
We define a function to calculate these metrics:
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
precision, recall, f1, _ = precision_recall_fscore_support(
labels, preds, average="weighted"
)
acc = accuracy_score(labels, preds)
return {"accuracy": acc, "f1": f1, "precision": precision, "recall": recall}Training (Fine-Tuning)
This is where the RoBERTuito model, which already understands general Spanish, learns the specific nuances of teacher complaints and the risks we defined.
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
warmup_steps=100,
weight_decay=0.01,
logging_dir="./logs",
logging_steps=10,
eval_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
)
num_train_epochs=3: How many times the model will read the entire dataset during training.per_device_train_batch_size=8: The number of examples (rows of text) the model processes before updating its internal weights.per_device_eval_batch_size=8: The same as above, but for the evaluation phase.warmup_steps=100: During the first 100 steps, the model uses a very low "learning rate" that increases gradually. This prevents the model from making sharp errors at the start before it "knows" the data.weight_decay=0.01: Helps prevent overfitting by penalizing parameters that become too large.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
compute_metrics=compute_metrics,
)Saving the Model
model.save_pretrained("./fine_tuned_model")
clf = pipeline("text-classification", model="./fine_tuned_model")
print(clf("He is a very good teacher, one of the best in the university."))We save the trained model into a folder. Then, we use a pipeline to test it with new comments.