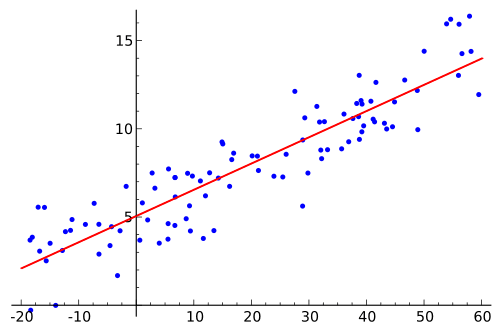
1. Preparando las herramientas
Antes de empezar, necesitamos algunas librerías. Importamos pandas que nos servirá para manipular los datos de forma sencilla y sklearn para manejar el tema de Machine Learning, los modelos, métricas y validación.
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error, r2_score, mean_squared_error2. Carga y Limpieza de Datos
Un modelo de inteligencia artificial es tan bueno como los datos que recibe. Si le das basura, predice basura.
Aquí puedes descargar un archivo salary.csv de una lista de salarios para que puedas seguir este ejercicio. Te recomiendo que sigas el ejercicio paso paso en Google Colab.
df = pd.read_csv("salary.csv")
df.isnull().sum() # Cuenta cuántos datos faltan (vacíos).
df.dropna(inplace=True) # Elimina las filas que tienen valores vacíos.3. Feature Engineering
Aquí defines qué causa qué. En este caso, asumimos que los Años de Experiencia determinan el Salario.
features = ['Years of Experience']
X = df[features] # Variable independiente
y = df['Salary'] # Variable dependiente- Por convención matemática se suele usar una matriz
Xeyun vector.
4. Test/Train Split
En esta etapa debemos dividir nuestro dataset en dos partes, la parte que usaremos de entrenamiento y la que usaremos de pruebas. Normalmente asignamos un 30% del dataset para los tests.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)random_state=42: Asegura que, si corres el código de nuevo, la mezcla de datos sea siempre la misma y tus resultados sean replicables.
5. Entrenamiento del Modelo
Aquí es donde ocurre la "magia". El modelo intenta encontrar la línea recta que mejor se ajuste a los puntos.
model = LinearRegression()
model.fit(X_train, y_train)- El método
.fit()calcula internamente la ecuación de la recta: donde es el aumento de salario por cada año de experiencia.
6. Evaluación
Ahora le pedimos al modelo que adivine los salarios de los datos que guardamos en el paso 4 y comparamos sus respuestas con la realidad.
predictions = model.predict(X_test)
print(f"R²: {r2_score(y_test, predictions):.2f}")
print(f"MAE: {mean_absolute_error(y_test, predictions):.2f}")
print(f"RMSE: {np.sqrt(mean_squared_error(y_test, predictions)):.2f}")| Métrica | ¿Qué significa? |
|---|---|
| R2 | Qué tan bien explica el modelo la variación. 1.0 es perfecto, 0.0 es como adivinar al azar. |
| MAE | El error promedio en dinero. Si es 500, el modelo se equivoca por $500 en promedio. |
| RMSE | Similar al MAE, pero penaliza mucho más los errores grandes (los "outliers"). |
Si quieres investigar más sobre las métricas, lee esto: https://byandrev.dev/es/blog/performance-metrics-in-machine-learning.
7. Visualización
Finalmente, graficamos los resultados.
plt.figure(figsize=(8,6))
sns.scatterplot(x=y_test, y=predictions, color='green')
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'r--')
plt.xlabel("Real Salary")
plt.ylabel("Predicted salary")
plt.title("Predicted vs Real - Linear Regression")
plt.grid(True)
plt.show()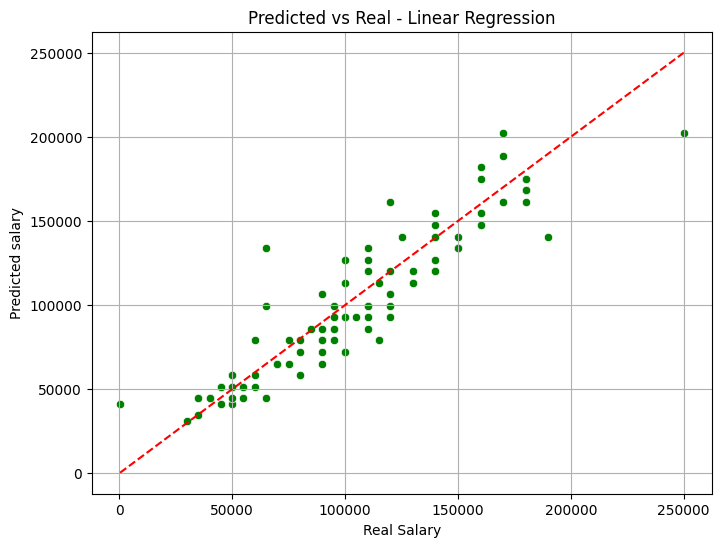
Gráfica de un modelo de Regresión Lineal.
- La línea roja representa la "perfección" (donde la predicción es igual a la realidad). Cuanto más cerca estén los puntos verdes de la línea roja, mejor es tu modelo.