
¿Cómo aprende una máquina?
La manera que funciona el aprendizaje automático principalmente es de 3 formas según como procesan la información:
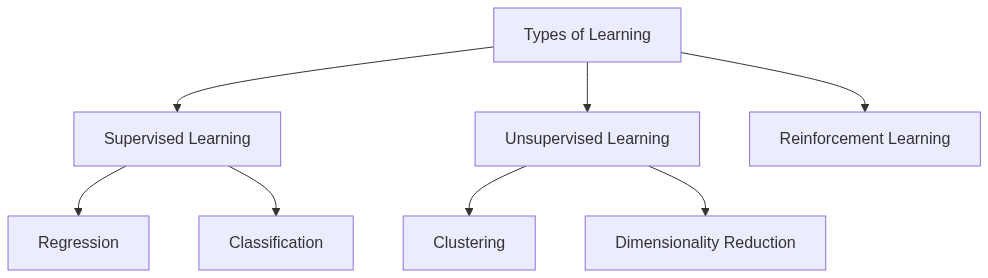
Tipos de aprendizaje en Machine Learning.
- Supervisado: Es como enseñar con ejemplos. Los modelos aprenden mediante ejemplos etiquetados para realizar las predicciones. Si quieres predecir cuántos goles hará un equipo según sus tiros a puerta, usas Regresión Lineal. Si prefieres saber la probabilidad de victoria usas Regresión Logística.
- No supervisados: Los modelos encuentran patrones en los datos que no tienen etiquetas previas.
- De refuerzo: Es el clásico sistema de "premio y castigo". Se basa en sistemas de premios cuando un modelo acierta en sus acciones.
Video explicativo de tipos de aprendizaje en Machine Learning.
Limpieza de datos
Esta es una etapa clave en el Machine Learning, antes de entrenar un modelo es importante prepara los datos, por ejemplo haciendo uso de codificación, escalado y visualización.
Si una variable mide goles (0-5) y otra pases (0-500), el modelo se confunde. Usamos Normalización (ajustar todo entre 0 y 1) o Estandarización para que todo esté en la misma escala.
| Característica | Normalización (Min-Max) | Estandarización (Z-score) |
|---|---|---|
| Rango de salida | Generalmente [0,1] o [−1,1] | No tiene límites (pero suele estar entre −3 y 3) |
| Sensibilidad a Outliers | Muy sensible (los valores extremos dictan el rango) | Mucho más robusta |
| Algoritmo ideal | KNN, Redes Neuronales | Regresión Lineal, Logística, PCA |
Los outliers son valores atípicos. Por ejemplo, si existen 100 jugadores y uno corre 100 km y los otros jugadores corren entre 10 y 20 km, ese seria un outlier.
También es muy útil emplear histogramas para ver la distribución de datos y heatmaps para identificar la fuerza de la relación entre variables.
Ejemplo de un Heatmap
Selección de características
Es importante entender que no todos los datos son útiles para lo que queremos conseguir, por esto hay que refinarlos. Para hacer esto podemos:
- Ingeniería de características: Crear nuevas variables a partir de las existentes para ayudar al modelo a descubrir patrones más profundos.
- Selección: Simplificar el modelo quedándose solo con las variables que aportan valor real.
Aquí te dejo un ejemplo de transformar datos crudos en información mas útiles para los modelos:
| Input | Feature Engineering | ¿Por qué es útil? |
|---|---|---|
| Goles anotados + Minutos jugados | Goles por cada 90 minutos | Permite comparar la eficiencia de un delantero que juega mucho frente a uno que entra de cambio. |
| Tiros a puerta + Goles | Efectividad de tiro (%) | Indica qué tan letal es un jugador, no solo cuánto tira. |
| Fecha del partido | ¿Es fin de semana? | Ayuda a ver si el rendimiento del equipo cambia según el día de la semana. |
¿Cómo sabemos si nuestro modelo es bueno?
Es recomendable dividir los datos en Entrenamiento (Train), donde el modelo aprende, y Prueba (Test), generalmente un 20% de los datos para verificar el rendimiento esto para ver si de verdad aprendió o solo memorizó.
Overfitting
Esto ocurre cuando un modelo de IA se vuelve "demasiado experto" en los datos de entrenamiento, hasta el punto de que pierde la capacidad de entender datos nuevos.
Imagina que un estudiante se prepara para un examen de matemáticas. En lugar de aprender las fórmulas y la lógica detrás de los problemas, decide memorizar cada ejercicio y cada respuesta de su libro de texto.
Si le haces una pregunta en el entrenamiento exactamente igual a la del libro, sacará un 10. Pero si en el examen le cambian un solo número o le plantean un escenario ligeramente distinto, el estudiante fallará por completo porque no sabe razonar, solo sabe repetir lo que memorizó.
¿Quieres ver esto en código? He documentado un proyecto paso a paso donde aplico todo esto para predecir resultados de fútbol: https://byandrev.dev/es/blog/machine-learning-football-project