
Es como tener un asistente personal para la IA, que te permite:
- Descargar modelos: Ollama te permite encontrar y descargar rápidamente modelos pre-entrenados.
- Probar sin complicaciones: Elimina la necesidad de configurar entornos de desarrollo complicados.
1. Instalar Ollama
curl -fsSL https://ollama.com/install.sh | shVisita la página oficial de Ollama para más información o para instalarlo en otro sistema operativo: https://ollama.com/download
2. Instalar un modelo en Ollama
Ollama tiene una sección donde puedes ver qué modelos puedes instalar, https://ollama.com/search. En este ejemplo instalaré Gemma3, el cual es un modelo que puede correr en hasta una sola CPU.
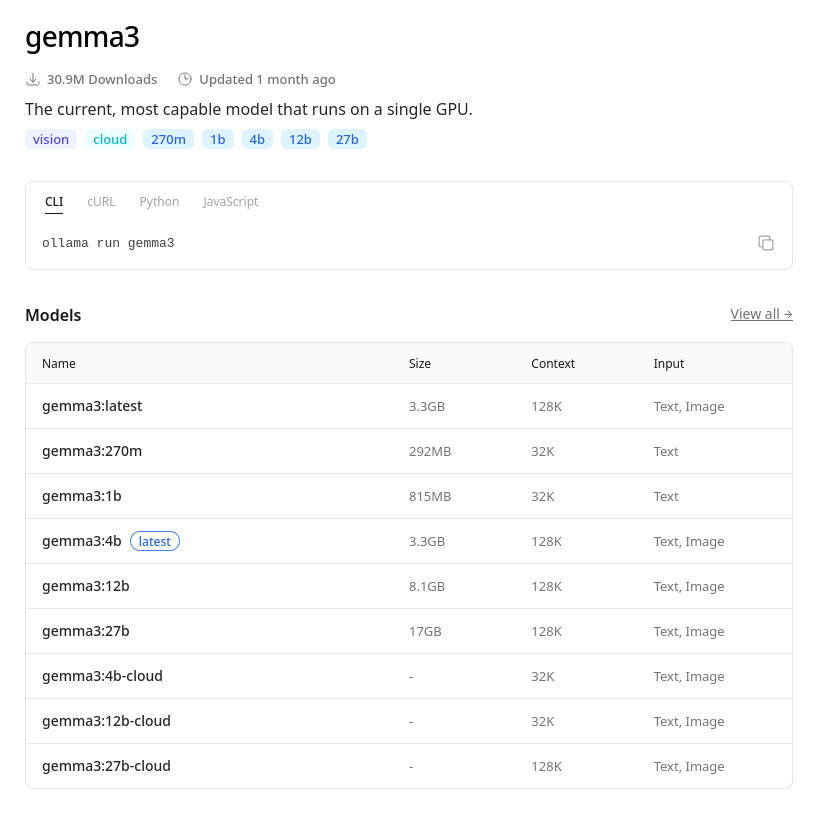
Modelo gemma3b en Ollama
Debemos ejecutar el siguiente comando en la terminal:
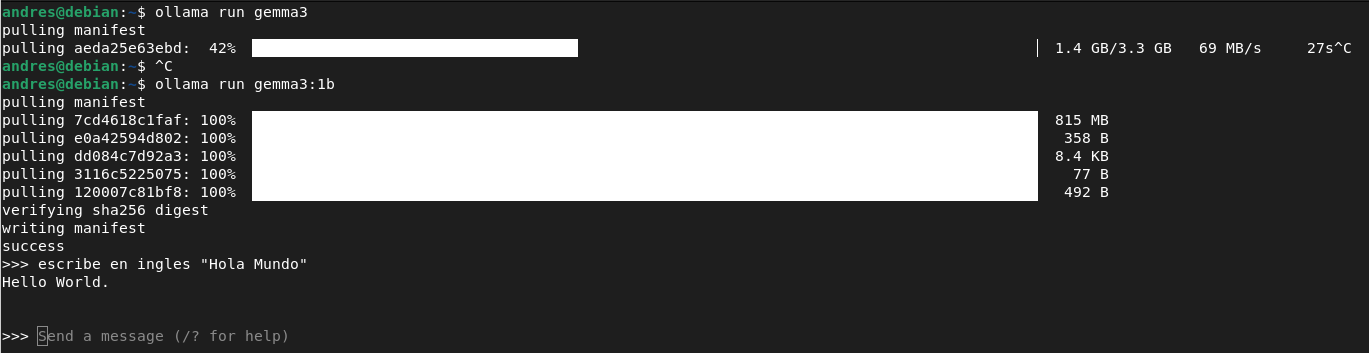
ollama run gemma3:1b Después de los ":" se coloca el modelo en específico, ya que los modelos pueden tener distintas versiones dependiendo del tamaño, el contexto, las entradas que soportan, etc.
¿Por qué usarías el 1B?
Principalmente por dos razones:
- Consumo de RAM mínimo, solo necesita unos 1.5 GB a 2 GB de RAM.
- Velocidad instantánea, es ideal para tareas donde la respuesta debe ser inmediata.
3. Ingresa tu prompt (mensaje)
Elige el prompt (la pregunta o instrucción que le das al modelo) que quieres que responda y el terminal Ollama te mostrará el texto generado por el modelo.
Enlaces
- Ollama: https://ollama.com/
- Gemma3B: https://deepmind.google/models/gemma/gemma-3/
- Ollama Docs: https://docs.ollama.app/