Importaciones y carga de datos
Se cargan las librerías necesarias:
- Pandas: Es una herramienta que nos permitirá el análisis y manipulación de datos con Python.
- PyTorch: La biblioteca que nos ayuda en los temas de aprendizaje automático para crear modelos de aprendizaje y redes neuronales.
- Transformers: Nos permite descargar, entrenar y utilizar modelos.
- scikit-learn: Nos servirá para obtener las métricas del modelo.
import os
import pandas as pd
import torch
from datasets import Dataset
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
from sklearn.model_selection import train_test_split
from transformers import (
AutoModelForSequenceClassification,
AutoTokenizer,
Trainer,
TrainingArguments,
)
df = pd.read_csv("data.csv")Preparación de etiquetas
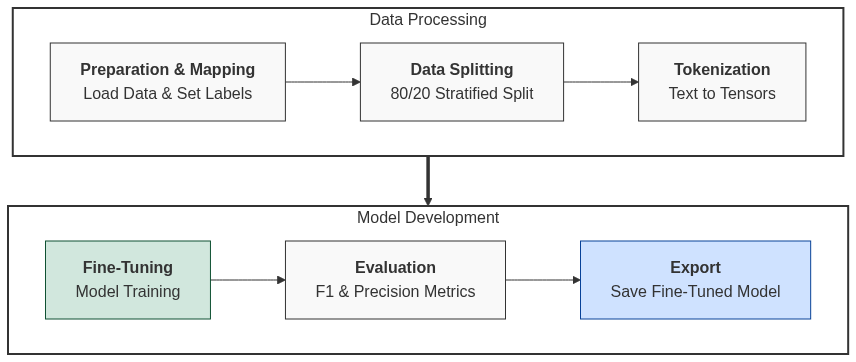
Aquí convertimos nuestros labels ("normal", "critico" y "muy_critico") en números (0, 1, 2). Esto en necesario porque las redes neuronales solo entienden números.
label_map = {"normal": 0, "critico": 1, "muy_critico": 2}
df["label"] = df["label"].map(label_map)División del dataset
Asignamos un porcentaje del dataset para las pruebas (tests) y otro para el entrenamiento, en este caso, 80% para el entrenamiento y 20% para las pruebas.
Esta división la hacemos para asegurarnos que el modelo realmente aprenda a identificar patrones y no solo memorice. Además, evitamos el overfitting (sobreajuste), porque si no hacemos una división no podremos saber si el modelo es bueno o no. Al ocultar un % de los datos, obligamos al modelo a buscar patrones más generales para que funcione en cualquier contexto.
train_df, test_df = train_test_split(
df, test_size=0.2, random_state=42, stratify=df["label"]
)El stratify nos asegura que tanto el grupo de entrenamiento como el de prueba tengan la misma proporción de casos, para evitar sesgos.
Tokenización
Este proceso es vital para traducir el texto a un formato que una computadora procese matemáticamente. Es el puente entre el texto y los tensores de PyTorch.
model_name = "pysentimiento/robertuito-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
def tokenize_function(examples):
return tokenizer(
examples["text"], padding="max_length", truncation=True, max_length=128
)
train_dataset = train_dataset.map(tokenize_function, batched=True)Configuración del modelo
Aquí se descarga la arquitectura del modelo que ya está diseñada específicamente para clasificar secuencias de texto.
Esta arquitectura está preparada para recibir una frase y entregar como salida una probabilidad para diferentes categorías.
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=3)num_labels=3: Al poner 3, estamos diciendo que quite la última capa de salida del modelo original y ponga una nueva que tenga exactamente 3 neuronas. Estas 3 neuronas corresponderán a los niveles: Normal, Crítico y Muy Crítico.
Métricas
Las métricas nos permiten saber qué tan bien funciona nuestro modelo, y es un proceso clave que siempre se debe hacer.
Existen 4 métricas clave:
Accuracy: Es el porcentaje total de aciertos.
Precision: Nos dice los casos que el modelo marcó como una etiqueta X y cuántos eran realmente así.
Recall: De todos los casos que existen en la realidad, ¿cuántos logró capturar el modelo?
F1-score: Nos dice qué tan bueno es el modelo detectando casos "Muy críticos" sin confundirlos con "Normales". Si el F1-score es alto, significa que el modelo es equilibrado y confiable para los tres niveles de riesgo.
Definimos una función que obtenga estas métricas:
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
precision, recall, f1, _ = precision_recall_fscore_support(
labels, preds, average="weighted"
)
acc = accuracy_score(labels, preds)
return {"accuracy": acc, "f1": f1, "precision": precision, "recall": recall}Entrenamiento (Fine-Tuning)
Aquí es donde el modelo RoBERTuito que ya sabe español general, aprende las particularidades de las quejas docentes y los riesgos que definimos.
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
warmup_steps=100,
weight_decay=0.01,
logging_dir="./logs",
logging_steps=10,
eval_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
)num_train_epochs=3: Cuántas veces el modelo leerá tu dataset completo durante el entrenamiento.per_device_train_batch_size=8: Indica cuántos ejemplos (filas de texto) procesará el modelo antes de actualizar sus pesos internos.per_device_eval_batch_size=8": Es lo mismo que lo anterior, pero para la fase de evaluación.warmup_steps=100: Durante los primeros 100 pasos, el modelo usará una "tasa de aprendizaje" muy baja que irá aumentando gradualmente. Esto evita que el modelo cometa errores bruscos al inicio del entrenamiento cuando aún no conoce los datos.weight_decay=0.01: Ayuda a prevenir el overfitting (sobreajuste). Penaliza los parámetros que se vuelven demasiado grandes.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
compute_metrics=compute_metrics,
)Guardar el modelo
model.save_pretrained("./modelo_fine_tuned")
clf = pipeline("text-classification", model="./modelo_fine_tuned")
print(clf("Es un muy buen docente, de los mejores de la universidad."))Guardamos el modelo entrenado en una carpeta. Luego se usa una pipeline para probarlo con comentarios nuevos.