
He estado adentrándome en el Machine Learning y en este ejercicio haré uso del clasificador de Naive Bayes para clasificar reviews de usuarios en positivas o negativas. Naive Bayes es una muy buena opción para comenzar con este ejercicio, pero es importante decir que tecnologías como los Transformers son mejor opción hoy en día.
Naive Bayes
Naive Bayes es un algoritmo de clasificación supervisada para predecir a qué categoría pertenece un dato, basándose en probabilidades. El nombre proviene de la palabra Bayes, que hace referencia al Teorema de Bayes, y el Naive por la ingenuidad de su lógica.
Tiene como ventajas la velocidad y la eficiencia, pero por contraparte tiene la característica de la ingenuidad que asume que las palabras no tienen relación entre sí y no entiende el orden. Pero aun así el algoritmo tiene muchos casos útiles como:
- Filtros de spam.
- Análisis de sentimientos.
- Sistemas de recomendaciones.
Bibliotecas necesarias
Necesitamos tener instaladas las siguientes bibliotecas. Te recomiendo hacer este ejercicio en Google Colab para facilitar la configuración del entorno. Configura el Runtime como T4 para poder soportar todo el tamaño del csv.
- sklearn: fundamental para la vectorización de texto, el entrenamiento del modelo y el cálculo de métricas.
- nltk: la utilizaremos principalmente para la gestión y filtrado de stopwords.
- spaCy: nuestra herramienta principal para la tokenización.
- joblib: para guardar y cargar modelos de Machine Learning.
Preparación de los datos
Cargar el dataset
Puedes descargar el dataset aquí: reviews.csv. El dataset cuenta con 210000 reseñas y con las columnas: stars, review_body, language y product_category. Todas las reseñas están en español.
import pandas as pd
df = pd.read_csv('reviews.csv')Antes de hacer limpieza de datos, es importante entender cómo se distribuyen nuestras etiquetas. Visualizaremos la frecuencia de las puntuaciones para verificar si contamos con un dataset balanceado.
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(8, 4))
sns.countplot(x='stars', data=df)
plt.title('Distribution of Scores')
plt.show()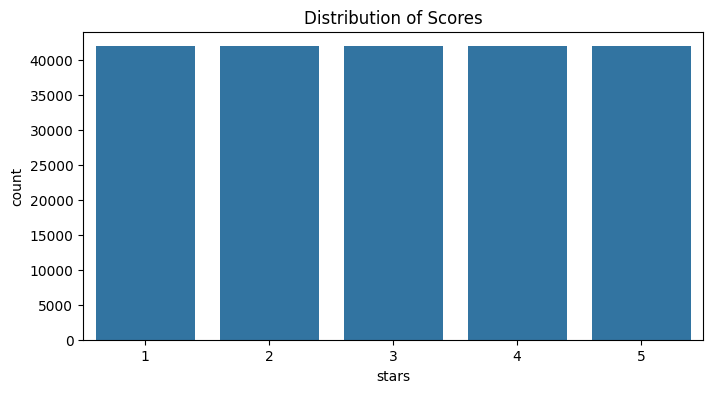
Un desbalance significativo (por ejemplo, tener muchas reseñas de 5 estrellas y casi ninguna de 1) podría sesgar las predicciones de nuestro modelo. El dataset que tenemos esta balanceado.
Eliminar las filas nulas
Es necesario limpiar el dataset eliminando las filas que no contienen información completa porque pueden generar errores.
# Conocer la cantidad de valores nulos por columna
df.isnull().sum()
# Eliminar filas que contengan valores nulos
df.dropna(inplace=True)Limpieza y Normalización de Texto
El siguiente paso es estandarizar el contenido. Crearemos una función de limpieza que utilice expresiones regulares para eliminar el ruido de los datos.
import re
import string
def preprocess_text(text):
"""
Realiza una limpieza del texto: conversión a minúsculas,
eliminación de ruido (URLs, HTML, etiquetas) y normalización de caracteres.
"""
# Estandarización a minúsculas
text = str(text).lower()
# Eliminar contenido entre corchetes (ej. etiquetas o referencias)
text = re.sub(r'\[.*?\]', '', text)
# Eliminar URLs y direcciones web
text = re.sub(r'https?://\S+|www\.\S+', '', text)
# Eliminar etiquetas HTML
text = re.sub(r'<.*?>+', '', text)
# Reemplazar saltos de línea por espacios
text = re.sub(r'\n', ' ', text)
# Eliminar palabras que contienen dígitos
text = re.sub(r'\w*\d\w*', '', text)
# Eliminar espacios en blanco sobrantes
text = text.strip()
return text
df["clean_review"] = df["review_body"].apply(preprocess_text)Remover las Stopwords
Esta técnica elimina las palabras comunes como "el", "la", "de". Las cuales no aportan significado semántico para clasificar los textos.
Al eliminarlas, incrementamos la velocidad de procesamiento y enfocamos el modelo en los términos importantes. Pero se debe aplicar con cuidado, ya que en ciertos contextos (como el análisis de sentimiento) eliminar una negación puede alterar el sentido de la frase.
import nltk
from nltk.corpus import stopwords
# Descargamos el corpus de stopwords en español
nltk.download('stopwords')
stopword_es = set(stopwords.words('spanish'))- El corpus es un conjunto amplio y estructurado de textos. En este caso, descargamos una base de datos lingüística predefinida de
nltk.
Tokenización y Lematización
Para que un algoritmo entienda el texto, debemos descomponerlo y normalizarlo:
- La tokenización es el proceso de dividir el texto en unidades más pequeñas, llamadas tokens. Esto es esencial para análisis posteriores como el conteo de palabras o la vectorización.
- La lematización utiliza un diccionario para reducir cada palabra a su raíz lingüística o lema. Es mucho más preciso y mantiene el sentido, pero es más lento y requiere más recursos computacionales. Ejemplo: Las formas verbales "correrá", "corre" y "corriendo" se normalizan a "correr".
¿Por qué reducir el vocabulario? Buscamos eliminar el ruido y mejorar la eficiencia. Cada palabra se convertirá en una columna en nuestra matriz de características. Con el Stopwords y la lematización buscamos agrupar términos para obtener mayor eficiencia.
Debemos descargar el modelo de idioma específico para español (es_core_news_sm):
!python -m spacy download es_core_news_smimport spacy
nlp_es = spacy.load('es_core_news_sm')
def clean(text):
"""
Aplica tokenización, eliminación de stopwords y lematización
utilizando el modelo de spaCy.
"""
doc = nlp_es(text)
# Filtramos por stopwords y extraemos el lema de cada token
lemmatized = [token.lemma_ for token in doc if token.text.lower() not in stopword_es]
return " ".join(lemmatized).strip()
# Aplicamos la transformación al DataFrame
df["clean_review"] = df["clean_review"].apply(clean)Vectorizacion con TF-IDF
En esta etapa transformamos el texto en representaciones numéricas denominadas vectores. Existen varios métodos para hacer esto, pero en este ejemplo utilizaremos el TF-IDF (Term Frequency - Inverse Document Frequency).
El TF-IDF no solo mide qué tan frecuente es un término en un documento, sino qué tan relevante es en comparación con todo el conjunto de datos (corpus). Este método se basa en el modelo de Bag of Words, el cual analiza la importancia de los términos sin considerar su orden o el contexto.
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = df["clean_review"].tolist()
tfidf = TfidfVectorizer()
tfidf_matrix = tfidf.fit_transform(corpus)
print(f"Dimensiones de la matriz: {tfidf_matrix.shape}")Clasificador Naive Bayes
Ahora vamos a entrenar y evaluar un clasificador Naive Bayes para determinar el sentimiento (positivo o negativo) de las reseñas.
Primero debemos construir nuestra variable objetivo: si tiene más de 3 estrellas, será un comentario 1 (positivo) y si tiene menos de 3 estrellas, será 0 (negativo).
df["sentiment"] = df["stars"].apply(lambda x: 1 if x > 3 else 0)División del dataset
Para garantizar que nuestro modelo sea capaz de generalizar, dividiremos nuestro dataset en dos grupos:
- Training set: los datos que el modelo utilizará para aprender las relaciones entre las palabras y el sentimiento.
- Test set: datos que el modelo nunca ha visto y que usaremos para validar su precisión final.
from sklearn.model_selection import train_test_split
X = tfidf_matrix
y = df["sentiment"]
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.2,
random_state=42
)- Definimos un 20% del dataset para la prueba final.
- El
random_state=42nos asegura que si se corre el código de nuevo, la división sea la misma y los resultados sean reproducibles.
Entrenamiento
Utilizaremos MultinomialNB el cual es una variante del algoritmo Naive Bayes especifica para trabajar con datos discretos donde se tengan conteo o frecuencia de eventos. Este trata cada palabra como un evento que ocurre una cierta cantidad de veces.
from sklearn.naive_bayes import MultinomialNB
nb_classifier = MultinomialNB()
nb_classifier.fit(X_train, y_train)Existen otras opciones como las siguientes:
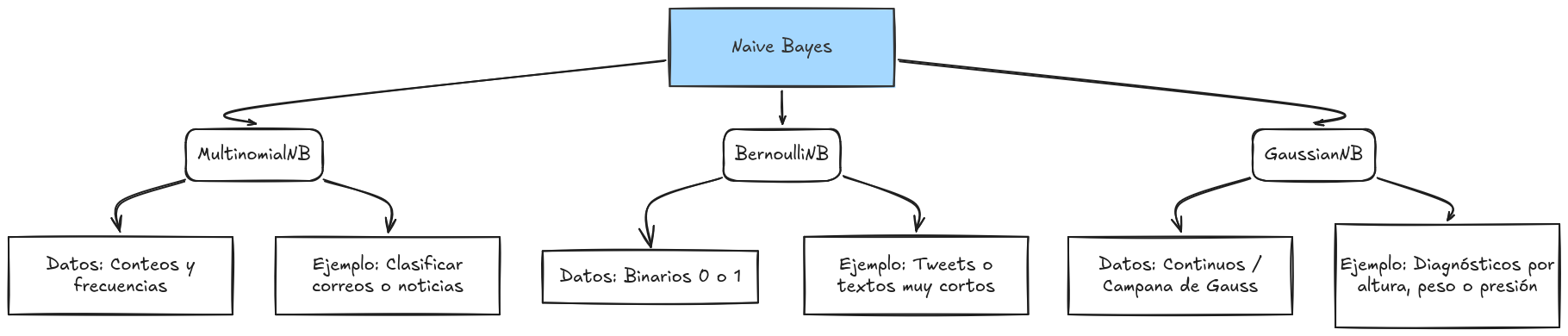
Evaluación del modelo
Una vez entrenado, debemos medir que tan bien funciona nuestro modelo y que desempeño tiene. Usaremos algunas métricas que nos ayudaran con esto:
- Accuracy: el porcentaje total de predicciones correctas.
- Precision: indica la calidad de las predicciones positivas. ¿Qué tan confiable es cuando dice "positivo"?
- Recall: mide la capacidad del modelo para identificar todos los casos positivos reales.
from sklearn.metrics import accuracy_score, classification_report
y_pred = nb_classifier.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
print("Reporte de clasificación:\n", classification_report(y_test, y_pred))Si quieres investigar más sobre las métricas, lee esto: https://byandrev.dev/es/blog/performance-metrics-in-machine-learning.
Guardar el modelo
Ahora guardaremos el modelo para usarlo en futuras ocasiones, para esto utilizamos la librería joblib.
import joblib
model_path = "/content/nb_classifier_model.pkl"
joblib.dump(nb_classifier, model_path)
print(f"Modelo exportado exitosamente en: {model_path}")Importar el modelo
loaded_model = joblib.load(model_path)Pruebas con datos reales
Para que el modelo entienda una nueva frase, esta debe pasar por el mismo proceso de vectorización (TF-IDF) que usamos durante el entrenamiento.
new_review = "Es un producto excelente, superó mis expectativas"
clean_review = clean(preprocess_text(new_review))
new_vector = tfidf.transform([clean_review])
prediction = loaded_model.predict(new_vector)
print(f"Reseña: '{new_review}'")
print(f"Predicción de sentimiento: {prediction[0]}")